프롬프트 엔지니어링 입문하기
그 동안 내가 생성형 AI를 사용하는 흐름은 아래와 같았다.
목차 보기
생성형 AI를 좀 생각하고 써보자
그 동안 내가 생성형 AI를 사용하는 흐름은 아래와 같았다.
- 에러 코드 -> copy & paste -> 해결 해줘
- "OO한 기능 구현해줘"
- "지금 이 코드가 ~인데, ~인 문제가 있어. 해결 방향을 제시해줘"
답없는 사용방식이었다.
AI를 잘 쓰기 위해 노력하지않고 게으르게 사용했는데, 늦었지만 지금이라도 학습하기로 했다.
프롬프트 유형
-
zero-shot
- 예시를 하나도 주지 않고 바로 질문하는 방식. "해줘" F에 가깝다.
"다음 문장을 영어로 번역해줘: '오늘 날씨 정말 좋다.'" -
one-shot
- 딱 하나의 예시를 보여주고 작업을 시키는 방식
"예시: '사과' -> 'Apple' '수박'을 영어로 번역해줘." -
few-shot
- 2개에서 10개 정도의 소량의 예시를 주는 방식인데, 최신 llm 모델에서는 2~3개면 된다고 한다.
"기분: 좋아 -> 긍정 기분: 그저 그래 -> 중립 기분: 너무 화나 -> 부정 기분: 날아갈 것 같아 -> (이곳에 답을 적어줘)" -
multi-shot/many-shot
- 수십 개에서 수백 개 이상의 많은 예시를 주는 방식
- 그냥 few-shot을 더 많이 하는 것이다.
-
CoT(Chain of Thought) - 연쇄적 사고
- AI에게 단순히 "답만 말해"가 아니라 "풀이 과정을 쓰면서 답해"라고 시키는 기술
- 정확도는 높아지는데, 토큰 소모량은 더 크다.
Q:
영희는 사과를 5개 가지고 있어. 그중 2개를 먹고, 시장에서 3개를 더 샀어.
영희는 지금 사과가 몇 개일까?
A:
영희는 처음에 5개가 있었고 2개를 먹었으니 3개가 남았어.
거기서 3개를 더 샀으니 3 + 3 = 6이야. 답은 6개.
Q: 철수는 공을 10개 가지고 있어. 친구에게 3개를 주고, 2개를 잃어버렸어.
철수는 지금 공이 몇 개일까?
이러면 AI는 Q-A 과정을 보고 중간과정 값을 도출해서 활용한다.
-
zero-shot CoT
- 예시(Shot)를 하나도 주지 않고, 특정한 문구 하나만 덧붙이는 방법
- 질문 끝에
단계별로 생각해봐(Let's think step by step)넣기
프롬프트 작성 전략
-
명확한 목표 및 목적 설정
전술 프롬프트 예시 작업 동사를 사용하여 원하는 작업 지정 "첨부된 연구 논문의 주요 결과를 요약하는 글머리기호 목록을 작성해 주세요." 원하는 출력 길이와 형식 정의 "기후 변화가 해안 지역사회에 미치는 영향에 대해 500단어 분량의 에세이를 작성해 주세요." 공유 대상 그룹 지정 "지속 가능성에 관심이 있는 청소년을 대상으로 한 유기농 피부 관리 신제품 라인의 제품 설명을 작성해 주세요." -
맥락 및 배경 정보 제공
전술 프롬프트 관련 사실 및 데이터 포함 "산업화 이전 시대 이후로 지구 온도가 섭씨 1도 올랐다는 점을 고려하여 해수면 상승이 미칠 수 있는 영향에 대해 논의해 주세요." 특정 출처 또는 문서 참조 "첨부된 재무 보고서를 바탕으로 지난 5년간의 회사 수익성을 분석해 주세요." 주요 용어 및 개념 정의 "기술 지식이 없는 사람에게 맞는 쉬운 용어로 양자 컴퓨팅의 개념을 설명해 주세요." -
구체적으로 작성
전술 프롬프트 예시 정확한 언어를 사용하고 모호함은 피함 "기후 변화에 대한 내용을 써 주세요." 대신 "더욱 엄격한 탄소 배출 규정의 시행을 주장하는 설득력 있는 에세이를 작성해 주세요."를 사용합니다. 가능하면 요청을 수치로 표현 "긴 시를 써 주세요." 대신 "사랑과 상실에 관한 주제를 탐구하는 14줄의 소네트를 써 주세요."를 사용합니다. 복잡한 작업은 더 작은 단계로 나누기 "마케팅 계획을 수립해 주세요." 대신 "1. 타겟층을 파악해 주세요. 2. 핵심 마케팅 메시지를 작성해 주세요. 3. 적절한 마케팅 채널을 선택해 주세요."를 사용합니다. -
페르소나 설정 (Role Prompting)
AI에게 단순한 비서가 아닌 특정 직업이나 성격을 부여한다. gemini gems 만드는 것 처럼 역할 부여하면 정확도를 높일 수 있다.
"너는 10년 차 시니어 소프트웨어 엔지니어야.
주니어 개발자가 이해하기 쉽게 코드 리뷰를 해줘."
RAG(Retrieval-Augmented Generation, 검색 증강 생성)
외부 소스를 참고해 답변하도록 하는 기술. 파인튜닝이 재교육이라면, RAG는 도서관에 집어넣는 방식
학습 데이터 이후 정보를 먹여서 참조할 지식 범위를 제한하는 방식으로 할루시네이션을 최소화할 수 있게 된다.(발생 가능성이 0은 아니다.)
- 검색 (Retrieval): 질문과 관련된 신뢰할 수 있는 외부 데이터(문서, DB, 웹 등)에서 관련 내용을 검색
- 증강 (Augmentation): 찾아온 정보와 사용자의 질문을 하나로 합침 (예: "이 문서 내용을 참고해서 질문에 답해줘: [문서 내용] + [질문]")
- 생성 (Generation): 합쳐진 정보를 바탕으로 AI가 최종 답변을 생성
5단계로 나눠볼 수 있다.
- 데이터 준비: 문서 자르기 (Chunking) 방대한 양의 PDF나 텍스트 파일을 AI가 한꺼번에 모두 읽기는 어렵다. 따라서 문서를 의미 있는 단위(문단 등)로 세분화하는 작업이 필요하다. 답변에 반드시 필요한 '핵심 조각'만을 정확하게 골라내기 위함이다.
- 임베딩 (Embedding): 글자를 숫자로 바꾸기 컴퓨터는 글자 자체보다 '의미'를 숫자로 표현했을 때 더 효과적으로 이해한다. 텍스트 조각들을 고차원 공간상의 좌표인 벡터(Vector)로 변환한다. 비슷한 의미를 가진 문장들은 좌표 공간 내에서 서로 가까운 거리에 위치하게 된다.
- 벡터 데이터베이스 (Vector DB) 저장 숫자로 변환된 문서 조각(벡터)들을 보관하는 특수한 저장소이다. 일반적인 데이터베이스와 달리 '의미가 유사한 것'을 매우 빠르게 찾아낼 수 있도록 최적화되어 있다.
- 검색 및 추출 (Retrieval) 사용자가 질문을 하면 해당 질문 역시 동일하게 숫자(벡터)로 변환한다. 그 후 벡터 DB에서 질문과 가장 가까운 위치에 있는 문서 조각들을 검색하여 추출한다. "우리 회사 복지 정책 알려줘"라고 질문하면, DB에서 '휴가', '경조사', '복지포인트' 관련 조각들을 찾아온다.
- 답변 생성 (Generation) 마지막으로 AI(LLM)에게 추출된 데이터를 바탕으로 명령을 내린다.
AI에게 전달되는 프롬프트 예시: "여기에 검색을 통해 찾아온 문서 조각들이 있다: [추출된 문서들]. 이 내용을 바탕으로 사용자의 질문 '[질문]'에 대해 친절하게 답변하라."
XML 태그로 제어(claude나 gpt에 유리)
프롬프트가 길어지면 AI는 어디까지가 '설명'이고, 어디서부터 '예시'인지, 또 '출력 형식'은 무엇인지 혼동하기 시작하는데, 이때 <instructions>, <example>, <formatting>, <rules>과 같은 태그를 사용하여 프롬프트의 다양한 부분을 영역 인식하게 해 명확하게 분리하면 지시사항을 예제나 컨텍스트와 혼동하지 않게된다.
답변 시 태그를 재사용해서 쓸 수도 있게 할 수 있다.
<task>
다음 수학 문제를 풀고 정답을 말해줘.
</task>
<prompt_template>
너는 반드시 아래 형식을 지켜서 대답해야 해:
1. <thinking> 태그 안에 문제를 풀기 위한 논리적 추론 과정을 적어라.
2. <answer> 태그 안에 최종 결론만 적어라.
</prompt_template>
<question>
사과 5개가 있고 친구가 2개를 가져갔어. 그 후 내가 3개를 더 샀다면 남은 사과는?
</question>
정해진 태그는 따로 없고 사용할 맥락에 맞게 넣어주면 되는데 계층적 콘텐츠의 경우 <outer><inner></inner></outer>와 같이 태그를 중첩해야 좋다.
이걸 멀티샷에 적용하면 아래처럼 된다.
수학 문제를 해결하는 방법을 보여드린 다음, 비슷한 문제를 해결해 주세요.
문제 1: 80의 15%는 얼마입니까?
<thinking>
80의 15%를 구하려면:
1. 15%를 소수로 변환: 15% = 0.15
2. 곱하기: 0.15 × 80 = 12
</thinking>
답은 12입니다.
이제 이 문제를 해결해보세요:
문제 2: 240의 35%는 얼마입니까?
토큰 비용 줄이기(API 말고)
프롬프트 압축 및 최적화
프롬프트의 길이를 줄이는 것은 가장 직접적인 비용 절감 방법이다.
- 불필요한 수식어 제거: "정중하고 친절하게 아주 자세히 설명해 줄 수 있니?"보다는 "전문적인 톤으로 요약해줘"와 같이 명확하고 짧은 지시어를 사용
- XML 태그 및 구조 활용: 긴 문장으로 설명하는 대신
<rules>, <task>와 같은 태그를 사용하면 AI가 구조를 더 빨리 파악하여 적은 설명으로도 의도를 정확히 이해 - JSON/Markdown 활용: 결과물을 받을 때 "결과를 출력할 때 첫 번째 줄에는 무엇을 쓰고..." 식으로 길게 설명하지 말고, "출력 형식: JSON"이라고 명시한 뒤 스키마 예시를 하나만 주는 것이 효율적
컨텍스트 관리
- 대화 요약: 대화가 길어질수록 이전 대화 내용이 모두 토큰으로 포함되어 비용이 기하급수적으로 늘어나게 되므로, 이전 대화 전체를 보내지 말고, 핵심 내용만 요약해서 다음 프롬프트의 컨텍스트로 넘기는 것을 추천한다.
- 요약 시에 소비되는 토큰이 있긴하지만, 이후 대화에서 사용할 토큰 수를 줄이기 위한 trade-off
- 요약을 일정 주기로 한다면, 매번 전체 요약이 아니라 기존 요약 + 추가 대화로 요약하면 됨
- 슬라이딩 윈도우: 가장 최근의 대화 3~5개만 유지하고 오래된 대화는 삭제
- RAG 최적화: 외부 문서를 참조할 때 문서 전체를 넣지 말고, 질문과 가장 관련 있는 최소한의 Chunk만 선별
토큰 계산 방식
영어와 한국어의 토큰 소비량은 다르다.
영어의 경우 apple처럼 자주 쓰이는 단어는 단어 전체가 하나의 토큰이 되기도 하고, happily는 happi + ly처럼 의미 있는 단위로 쪼개지는데, 한국어의 경우 단어 뒤에 조사가 붙고(밥을, 밥도, 밥은) 동사의 활용이 복잡하여 경우의 수가 너무 많다.
AI 학습 데이터 중 한국어 비중이 영어보다 적다 보니, 한국어는 영어처럼 효율적으로 뭉치지 못하고 음절(글자) 단위나 심지어 자음/모음 단위로 쪼개지는 경우가 많아서 영어로 한 단어가 1토큰일 때, 한국어는 1토큰일수도 훨씬 많은 토큰을 먹을 수도 있다.
그리고 utf-8인코딩에서 한국어가 차지하는 용량이 영어보다 3배크다. 사용할 LLM의 토크나이저가 한국어 처리를 잘 못한다면 토큰 폭탄이 발생할 수 있게 되는 것이다.
⇒ 될 수 있으면 영어로 질문하고, 영어로 답변 받는 게 토큰 아끼는 방법 중 하나다.
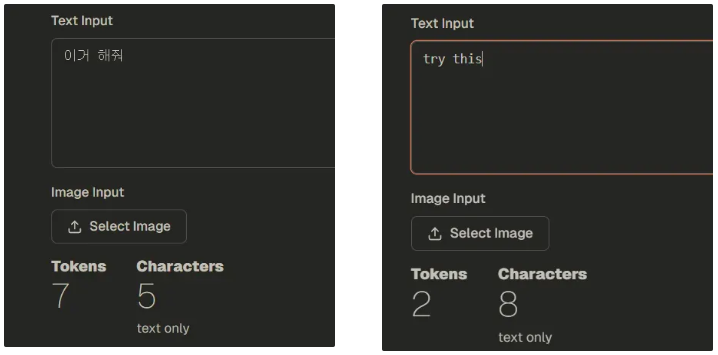
2024년 11월 claude 기준이라서 그렇게 신뢰있는 결과는 아닌데, 차이가 있음은 명확하다.
영어로 전부 다 쓰던가, 좀 더 편하게 쓰려면 지시 + 규칙은 영어, 내용은 한국어로 구성할 것.
아니면 설명하지 말고 목록으로만 출력 같은 출력 제한 프롬프트를 끼워서 출력 때 발생하는 토큰 낭비를 줄일 수도 있다.
MCP(Model Context Protocol)
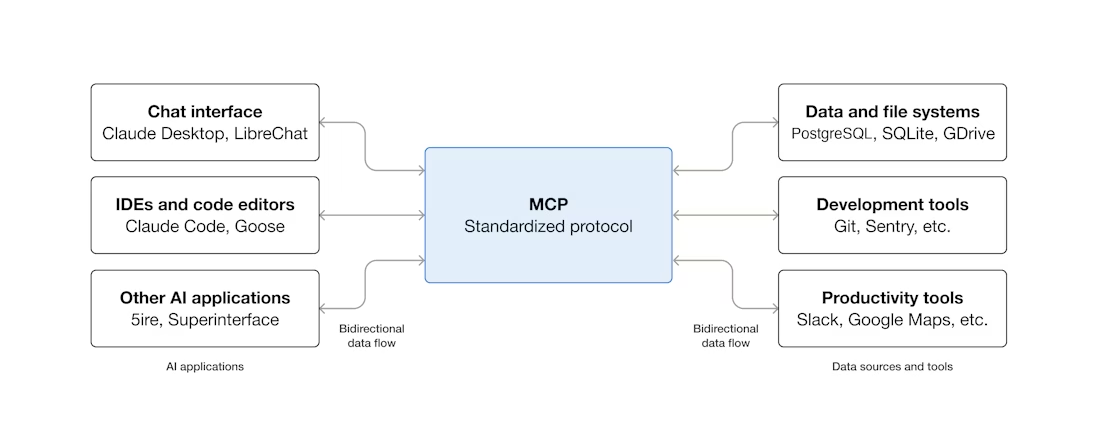
MCP는 AI 애플리케이션을 외부 시스템에 연결하기 위한 오픈 소스 표준
Claude나 ChatGPT와 같은 것들이 데이터 소스, 도구(피그마같은), 그리고 워크플로우에 연결될 수 있는 것임. → 일종의 툴콜링
RAG보다 더 큰 범위의 기능
| 기능 | MCP | RAG |
|---|---|---|
| 기본 목표 | LLM이 외부 도구, 데이터 소스, 서비스에 액세스하고 상호작용하여 정보 검색과 함께 작업을 수행할 수 있도록 양방향 통신을 표준화합니다. | 응답을 생성하기 전에 신뢰할 수 있는 기술 자료에서 관련 정보를 검색하여 LLM 응답을 개선합니다. |
| 메커니즘 | LLM 애플리케이션이 외부 함수를 호출하거나 특수 서버에서 정형 데이터를 요청할 수 있는 표준화된 프로토콜을 정의하여 작업 및 동적 컨텍스트 통합을 지원합니다. | 사용자의 쿼리를 사용하여 기술 자료 또는 데이터 소스에서 정보를 가져오는 정보 검색 구성요소를 통합합니다. 이렇게 검색된 정보는 LLM의 프롬프트를 보강합니다. |
| 출력 유형 | LLM이 도구에 대한 구조화된 호출을 생성하고 결과를 수신한 다음 해당 결과와 작업을 기반으로 인간이 읽을 수 있는 텍스트를 생성할 수 있도록 합니다. 실시간 데이터와 함수도 포함될 수 있습니다. | LLM은 외부 문서의 쿼리와 관련된 텍스트로 보강된 학습 데이터를 기반으로 응답을 생성합니다. 사실 정확성에 중점을 두는 경우가 많습니다. |
| 상호작용 | 외부 시스템에서 활발한 상호작용과 작업 실행을 위해 설계되었으며, LLM이 외부 기능을 '사용'할 수 있는 '문법'을 제공합니다. | 주로 텍스트 생성을 위한 정보의 수동 검색에 사용되며, 일반적으로 외부 시스템 내에서 작업을 실행하는 데는 사용되지 않습니다. |
| 표준화 | AI 애플리케이션이 LLM에 컨텍스트를 제공하는 방식에 대한 개방형 표준으로, 통합을 표준화하고 커스텀 API의 필요성을 줄입니다. | LLM을 개선하기 위한 기법 또는 프레임워크이지만, 여러 공급업체 또는 시스템 전반에서 도구 상호작용을 위한 범용 프로토콜은 아닙니다. |
| 사용 사례 | AI 에이전트는 작업(예: 항공편 예약, CRM 업데이트, 코드 실행)을 수행하고, 실시간 데이터를 가져오고, 고급 통합을 수행합니다. | 질의 응답 시스템, 최신 사실 정보를 제공하는 챗봇, 문서 요약, 텍스트 생성 시 할루시네이션 감소 |
MCP 호스트 (Host)
사용자가 직접 쓰는 AI 애플리케이션(Claude Desktop, Cursor, IDE 등) 전체 대화 흐름을 관리하고 최종적으로 사용자에게 답변을 보여주는 집 역할.
MCP 클라이언트 (사용하는 쪽) → host 안에 들어있을 수 있음
클라이언트는 보통 우리가 사용하는 AI 채팅 인터페이스나 개발 도구 안에 들어있다.
- 연결 관리: 여러 개의 MCP 서버를 하나로 묶어 AI 모델이 한꺼번에 인식할 수 있게 함.
- 권한 제어: 서버가 사용자의 컴퓨터에 너무 깊숙이 접근하지 못하도록 승인하거나 차단하는 문지기 역할
- 결과 전달: 서버가 가져온 데이터를 AI 모델이 이해하기 좋게 다듬어서 전달
MCP 서버 (일하는 쪽)
서버는 특정 기술이나 데이터에 특화된 작은 프로그램이다.
- 기능 제공: "나는 구글 캘린더를 읽을 수 있어", "나는 파이썬 코드를 실행할 수 있어"라고 자신의 능력을 명시
- 데이터 노출: 로컬 파일이나 데이터베이스(DB)에서 정보를 꺼내와 클라이언트에게 보냄
- 독립성: 서버는 AI가 어떻게 생겼는지 알 필요가 없고 MCP 표준 규격에 맞춰 데이터만 주고받으면 됨
- JSON-RPC 2.0
- stdio (표준 입출력): 주로 같은 컴퓨터 내에서 실행될 때 쓰임. 클라이언트가 서버 프로세스를 실행하고 텍스트를 주고받는 방식 (가장 흔한 방식)
- 만약 서버안에서 print같은 특정 std함수를 호출하면 mcp쪽 응답이랑 충돌나서 멈출 것
- HTTP + SSE (네트워크 연결): 서버가 외부 컴퓨터나 클라우드에 있을 때 사용합니다. 웹 브라우저가 서버와 통신하듯 데이터를 주고받음
MCP서버는 내가 로컬로 띄울 수도 있지만, 이미 다른 사람들이 만들어 둔 것을 사용할 수도 있다.
{
"mcpServers": {
"context7": {
"command": "npx",
"args": ["-y", "@context7/mcp-server"],
"description": "Live documentation lookup"
}
}
예를 들어 최신 공식 문서를 지키게 하기 위해 context7 mcp를 연결하려면 위에 처럼 json파일 수정하면 된다.
안좋은 사례
zero-shot
아주 자세하고 친절하게 초보자도 이해할 수 있게 설명해줘
LLM이 친절하기 위해서 길게 답변할 가능성이 높은데, 문제는 이후 답변도 계속 길게 할거라 토큰 낭비가 심하다.
고치려면
핵심만 bullet 5개 이내로 요약
각 항목 20자 이내
이렇게 입력 크기도 줄이고, 출력도 제한하는 게 효율적이다.
무지성 CoT
단계별로 생각해보고 과정을 모두 설명해줘
최신 모델은 내부 추론이 돌아가는데, 사람에게 설명하기 위한 쓸데없는 추론도 잡힐 가능성이 생겨 토큰 낭비가 발생한다.
계산은 내부적으로 수행하고
최종 결과만 출력
무지성 zero-shot
알아서 정리해줘
좋은 방향으로 개선해줘
목표가 없어서 원하는 수준의 답변이 안나올 가능성이 크다.
목표: A
제약: B
금지: C
다음 글은 claude skills로 간다.
참조 문서::
https://platform.claude.com/docs/ko/build-with-claude/prompt-engineering/use-xml-tags https://cloud.google.com/discover/what-is-prompt-engineering?hl=ko https://claude-tokenizer.vercel.app/ https://modelcontextprotocol.io/docs/getting-started/intro https://cloud.google.com/discover/what-is-model-context-protocol https://docs.cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-design-strategies?hl=ko